気づけば8月ももう終わりですね…(ギリギリの投稿です汗)
今月もあっという間に過ぎてしまった感じがしますが、私片平は、少し行き詰まっている本業の分類学からの現実逃避として「解析技術のレベルアップ」に努めていました。
思いつくままRで乱数を発生させてシュミレーションしてみたり、自分のデータをリサンプリングしてデータセットを再構築してみたり、そのために簡単な関数を作って動かせるか試してみたり…と、現在進行形で身につけつつあるスキルを今後どう活かせるか見当もつきませんが、今はこういった作業自体がとにかく楽しくなってきています。まだまだヒヨッコですが。
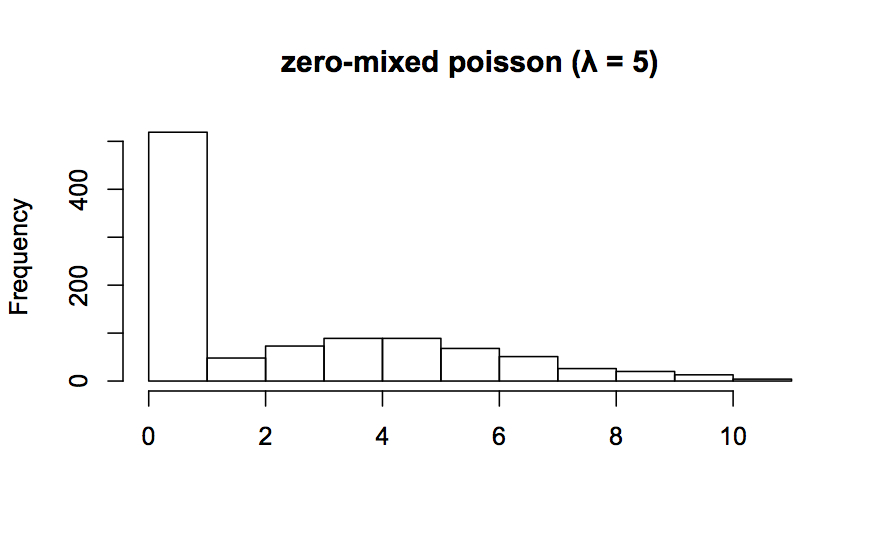
(たとえば…ポアソン分布にニセのゼロデータが混じっており、ゼロインフレなポアソン分布になってしまっているときの平均と分散のバラつきを知りたい場合は(なんのこっちゃ…ですが)、こんな感じで求めればいいのかな…とかです)

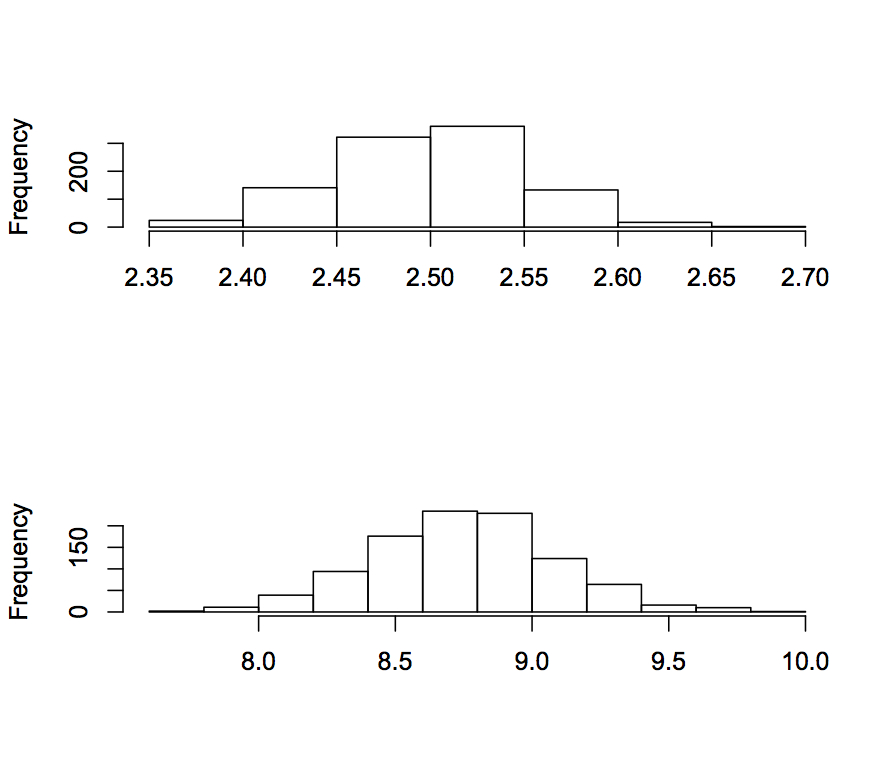
(出力される図は以下のような感じ。上が平均のバラつきで、下が分散のバラつき。ゼロが過剰に含まれてしまったせいで、分散の値が平均の値よりも明らかに大きくなってしまっているのがわかる)
これまでにもRで(非)線形モデルに触れてきたものの、ポンッと式を作ってパッと答えが得られてしまう手軽さに、勉強をすれどもすれども「ちゃんと理解していないまま動かしている部分があるのではないか」と一抹の後ろめたさを感じることが多々ありました(もちろん、理解したうえで命令しないと、そもそもRがスネて動いてくれないのですが…)。
そんなわけで、自分で一から関数を設計する作業ができることに加えて、フィールドから得られた汚いデータにもフレキシブルに対応できる「階層ベイズモデル」に手を出してみたいなぁ…と、淡い希望を以前から寄せていたのです。。。とはいえ、専門家に師事するわけでもなく、なんとなく気が向いたときに教科書を読んでみたり、ちょこっとWinBUGSやJAGSをいじってみたりして、でも動かなくてすぐ挫折してしまったり…と、あまり熱心ではなかったのですが、独学でちまちま理解を進めながら6年目にしてようやく動かせるようになってきました(おめでとう、パチパチパチ)。
階層ベイズに親しむことはもちろんなのですが、いろいろと学ぶ過程で嬉しい副産物が得られました。それは…
① 論文を読むのが早くなったこと
② 冒頭で述べた、Rのカスタムな使い方に慣れてきたこと
です。
①はいわずもがな、ですね。論文ではどんな目的でどんな統計解析を使ったのか、それによって筆者の主張したい仮説がきちんと支持されているのか、を読み取ることになるわけですが、統計の勉強が進めば進むほど解読がラクになっていきます。
②は、階層ベイズモデルで部品として使う乱数発生の関数に抵抗感が無くなって、自分で積極的に使ってみたいというポジティブな気持ちがうまく育ってくれた、ということです。結構気軽に使えるようになってきました。
いつもいつも全力で統計の勉強をするのはしんどいですが、長い目でみてコツコツと(ダラダラと?)学ぶスタイルは、マイペースな自分らしくて気に入っています。あとはこれが論文生産に直結してくれれば最高なのですが…泣。